

Mysql分库分表
Sharding-JDBC分库分表
最近做了一个B站番剧的爬虫项目,由于爬取弹幕信息的时候数据量过于庞大,放在一个表里面的话查询效率极慢,所以我便想将其分开存放。到网上了解了一下之后找到了一个方法——分库分表。中间也是遇到了很多的问题和bug,所以在这里总结一下方便后期查看,也为大家提一些解决bug的思路方法。ok,闲话不多说,开始展示吧!
1.引入依赖,我这里用的是Sharding-JDBC
<!--druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.1</version>
</dependency>
<!--Mybatis依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<!--Mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--分库分表相关依赖-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2.进行ShardingSphere相关配置
spring:
main:
allow-bean-definition-overriding: true #支持名称相同的bean的覆盖
sharding sphere:
props:
sql:
show: true #开启日志
datasource:
names: m,m1,m2 #数据库别名
m: #数据库相关配置
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/fanju?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: xxxx
m1:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/fanju1?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: xxxx
m2:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/fanju2?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: xxxx
sharding:
tables:
danmakus: #虚拟表名
actual-data-nodes: m$->{1..2}.danmakus$->{1..3} #真实表 用Groovy表达式表示
database-strategy:
inline:
sharding-column: cid #数据库分片列
algorithm-expression: m$->{cid % 2 + 1} #数据库分片规则
table-strategy:
inline:
sharding-column: cid #表分片列
algorithm-expression: danmakus$->{cid % 3 + 1} #表分片规则
keyGenerator: #主键值以雪花算法生成
type: SNOWFLAKE
column: id
default-data-source-name: m #默认数据库(这里可以不用配置,由于我第一次做的时候没想到分库,所以数据都存储在第一个库中,需要读取第一个库的数据进行操作,不配置的话他会随机访问其他库,找不到相应的表后会查找默认数据源,这里建议使用数据库的主从同步)
这样就完成了ShardingSphere的简单配置了,当然也可以自定义更加精确的分片算法,大家如果感兴趣的话可以自己了解一下,我当时因为简单配置就足够完成需求了所以就没有再进行精确配置。
代码写完了接下来就该聊聊项目过程中遇到的问题了
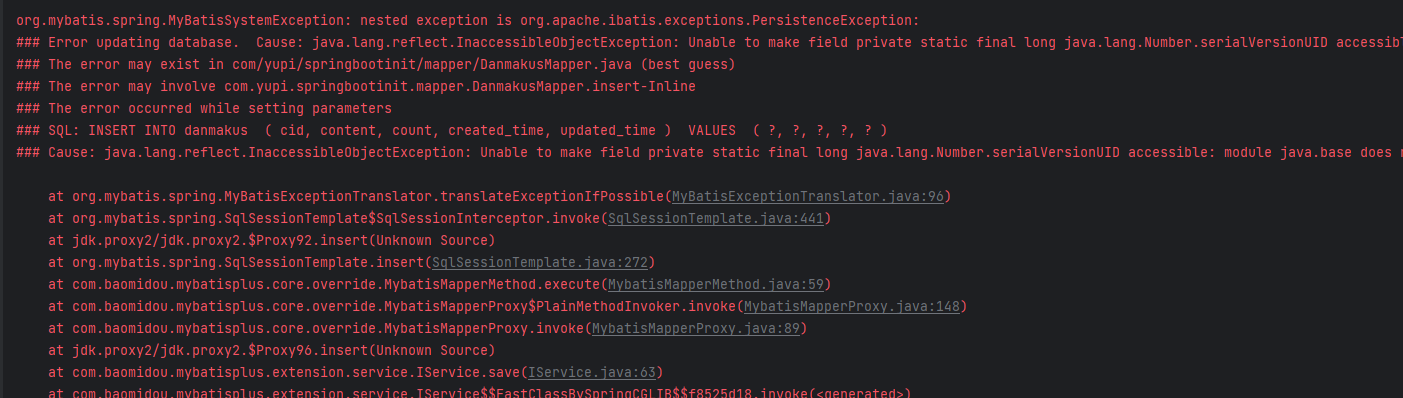
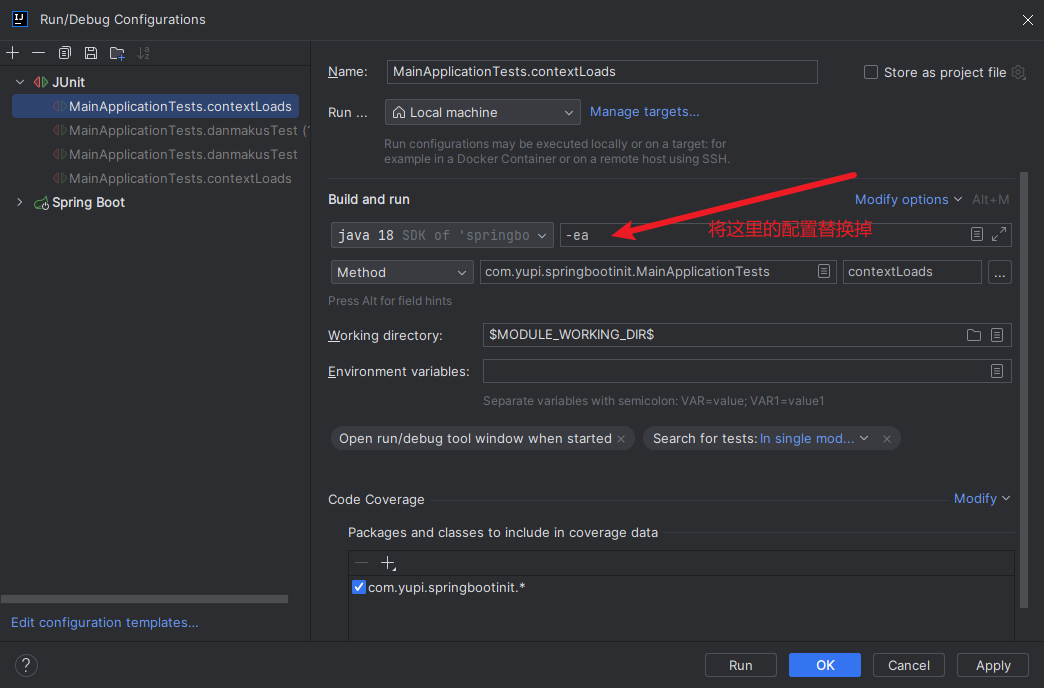
这里是因为我使用的版本是JDK18,而JDK9版本以后引入了module模块的概念,而不同module模块间是不允许使用反射来访问非public的字段/方法/构造函数(field/method/constructor),除非被访问的目标模块为反射设置open即允许自身被其他模块进行non-public反射访问。为了解决这个问题可以在启动前配置一下JVM选项,由于从网上找到了许多,所以在这里我就都贴给大家,大家可以按需使用,当然全都配置的话也可以。
--add-opens
java.base/java.lang=ALL-UNNAMED
--add-opens
java.base/java.lang.reflect=ALL-UNNAMED
--add-opens
java.base/java.lang.invoke=ALL-UNNAMED
--add-opens
java.base/java.math=ALL-UNNAMED
--add-opens
java.base/sun.net.util=ALL-UNNAMED
--add-opens
java.base/java.io=ALL-UNNAMED
--add-opens
java.base/java.net=ALL-UNNAMED
--add-opens
java.base/java.nio=ALL-UNNAMED
--add-opens
java.base/java.security=ALL-UNNAMED
--add-opens
java.base/java.text=ALL-UNNAMED
--add-opens
java.base/java.time=ALL-UNNAMED
--add-opens
java.base/java.util=ALL-UNNAMED
第一次写爬虫和分库分表相关的东西,可能有许多不对的地方,欢迎各位大佬指点。
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 程序员小航
阅读建议
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果
最近发布